牛客网sql实战题
全部实战题见:SQL数据库实战题_面试必刷+解析_牛客题霸_牛客网)
本文只收录有点难度的题目。
#SQL2
查找入职员工时间排名倒数第三的员工所有信息
有一个员工employees表简况如下:
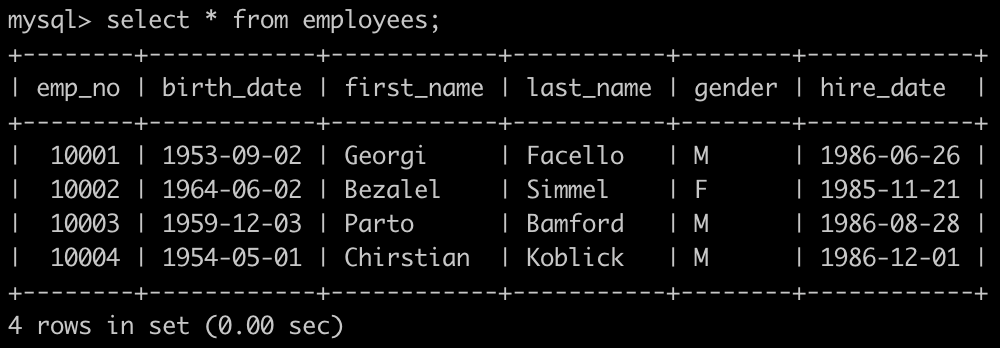
请你查找employees里入职员工时间排名倒数第三的员工所有信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
-- 方法一:这种不规范,
-- 只适用于倒数第三只有一位员工或虽有多位但只需要选其中一位员工的情况
select *
from employees
order by hire_date desc
limit 2,1 -- limit的offset从0开始数
-- 方法二:如果倒数第三有多位员工或为了适应性更广
select *
from employees
where hire_date = (
select distinct hire_date
from employees
order by hire_date desc
limit 2,1
)
-- 加了distinct会去重分组,多个相同入职日期会分为一组
-- 注意distinct会先于limit执行
-- 方法三:用窗口函数
select emp_no
,birth_date
,first_name
,last_name
,gender
,hire_date
from
(
select *
,dense_rank()over(order by hire_date desc) r
from employees
) a
where r = 3
|
本题虽然简单,但题目模糊,不知道排名倒数第三指的如何排序。鉴于牛客网将其归类为一道简单题,因此暂且认为方法一就行。但本题的解法已包括各种要求。
1.如果倒数第三只有一位员工或虽有多位但只需要选其中一位员工的情况,选择方法一
2.如果是在有多位员工时均要选出,排序符合dense_rank,可以用方法二
3.如果是情况一,可用窗口函数的row_number,如果是情况二,可用窗口函数的dense_rank。鉴于本题的情况,不可能属于rank的排序,因为如果是1224,那么题目就问错了
#SQL4
查找所有已经分配部门的员工的last_name和first_name以及dept_no
有一个员工表,employees简况如下:
有一个部门表,dept_emp简况如下:
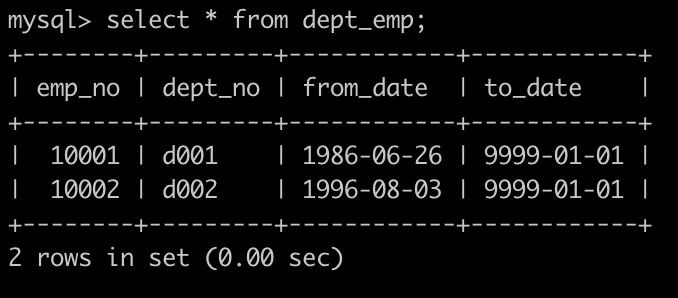
请你查找所有已经分配部门的员工的last_name和first_name以及dept_no,未分配的部门的员工不显示
1
2
3
4
5
6
7
8
9
10
|
-- 这题用内连接即可,
-- employees的员工如果连不上部门表的员工(里面的员工id都分配了部门id),
-- 那自然是没有被分配部门,
-- 使用左连接然后筛选是多此一举
select last_name
,first_name
,dept_no
from employees e
join dept_emp d
on e.emp_no = d.emp_no
|
#SQL10
获取所有非manager的员工emp_no
有一个员工表,employees简况如下:
有一个部门领导表dept_manager简况如下:
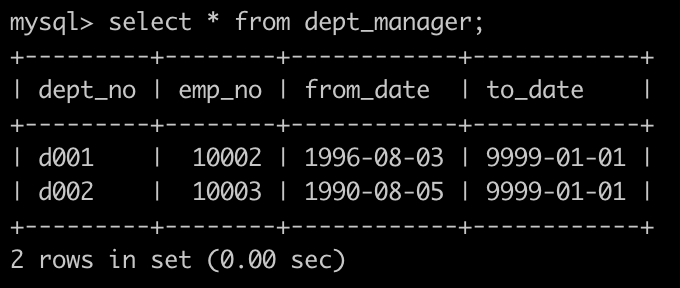
请你找出所有非部门领导的员工emp_no,输出格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
-- 方法一:排除法
select emp_no
from employees
where emp_no not in (
select emp_no from dept_manager
)
-- 方法二:表连接再选取法
select e.emp_no
from employees e
left join dept_manager d
on e.emp_no = d.emp_no
where dept_no is null
|
#SQL12
获取每个部门中当前员工薪水最高的相关信息
有一个员工表dept_emp简况如下:
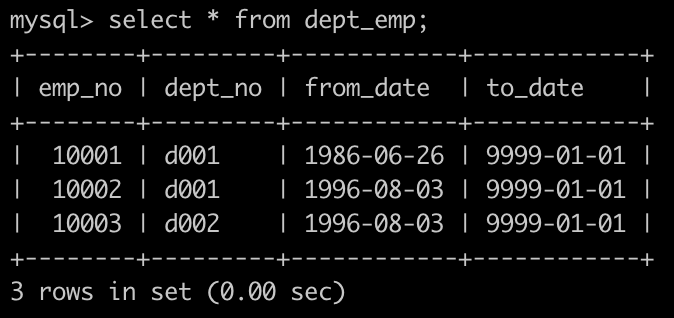
有一个薪水表salaries简况如下:
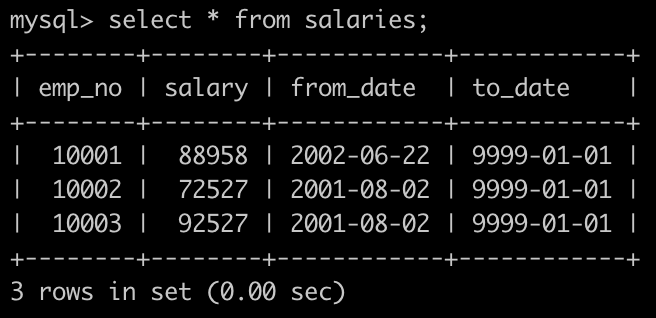
获取每个部门中当前员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门编号升序排列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
# 方法一:先取员工当前薪资表,再获取部门最高薪资表。
# 然后用薪资作为筛选条件对应以获取正确的员工编号。
SELECT t2.dept_no, t1.emp_no, t2.max_salary
FROM
(
SELECT e.emp_no , e.dept_no , s.salary
FROM dept_emp e
JOIN salaries s
ON e.emp_no=s.emp_no
) t1
JOIN
(
SELECT e.dept_no , MAX(salary) max_salary
FROM dept_emp e
JOIN salaries s
ON e.emp_no=s.emp_no
GROUP BY e.dept_no
) t2
ON t1.dept_no=t2.dept_no
WHERE t1.salary=t2.max_salary
ORDER BY t2.dept_no
# 方法二:窗口函数
select dept_no
,emp_no
,salary maxSalary
from
(
select d.dept_no
,d.emp_no
,salary
,dense_rank()over(partition by d.dept_no order by salary desc) r
from dept_emp d
join salaries s
on d.emp_no = s.emp_no
) a
where r = 1
order by dept_no
|
#SQL17
获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
有一个员工employees表简况如下:
有一个薪水表salaries简况如下:
请你获取薪水第二多的员工的emp_no以及其对应的薪水salary
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
-- 与SQL2一样,这类问题统称为获取倒数或顺数第n的xx,
-- 第一种方法是用order by与limit,第二种是窗口函数
-- 方法一:严谨版(通过distinct来去重排行)
select emp_no
,salary
from salaries
where salary = (
select distinct salary from salaries
order by salary desc
limit 1,1
)
-- 方法二:使用窗口函数
select emp_no
,salary
from
(
select *
,dense_rank()over(order by salary desc) r
from salaries
) a
where r = 2
|
#SQL18
获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
有一个员工employees表简况如下:
有一个薪水表salaries简况如下:
请你查找薪水排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,不能使用order by完成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
-- 此题与SQL17一样,只是要求不能使用order by完成,
-- 但第n多/少相当于n个select的max/min的嵌套,
-- 增加一个新方法:自连接排序法
-- 方法一:剥离
select e.emp_no
,s.salary
,last_name
,first_name
from employees e
join salaries s
on e.emp_no = s.emp_no
and s.salary =
(
select max(salary) -- 第二多
from salaries
where salary !=
(
select max(salary) -- 第一多
from salaries
)
)
-- 方法二:自连接
select e.emp_no
,s.salary
,last_name
,first_name
from employees e
join salaries s
on e.emp_no=s.emp_no
and s.salary =
(
select s1.salary
from salaries s1
join salaries s2 -- 自连接
-- 与比它大或等于的值连接,这样它有几个不同值即大于等于多少个值,即排行第几
on s1.salary<=s2.salary
group by s1.salary
having count(distinct s2.salary) = 2
)
-- v2.0这样直接与自连接结果表join更简洁
select e.emp_no
,a.salary
,last_name
,first_name
from employees e
join
(
select s1.emp_no,s1.salary
from salaries s1
join salaries s2 -- 自连接
-- 与比它大或等于的值连接,这样它有几个不同值即大于等于多少个值,即排行第几
on s1.salary<=s2.salary
group by s1.emp_no,s1.salary
having count(distinct s2.salary) = 2
) a
on e.emp_no=a.emp_no
|
综合SQL17和SQL18,“获取倒数或顺数第n的xx”类题通常有四种解法:
- order by与limit去重排序
- 多重子查询筛选
- 自连接
- 窗口函数的dense_rank
#SQL21
查找在职员工自入职以来的薪水涨幅情况
有一个员工employees表简况如下:
有一个薪水表salaries简况如下:
请你查找在职员工自入职以来的薪水涨幅情况,给出在职员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序
这题有点模糊,直接假设hire_date会对应from_date应该更好理解。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
-- "查找<在职>员工<自入职以来>的薪水涨幅情况",
-- 说明终点工资一定是to_date为9999-01-01的salary
-- 中间工资起伏不要紧,只需要求相对于入职时(hire_date)的涨幅就行了
select e.emp_no
,(s2.salary-s1.salary) as growth
from employees e
join salaries s1
on e.emp_no = s1.emp_no
and s1.from_date = e.hire_date
join salaries s2
on e.emp_no = s2.emp_no
and s2.to_date = '9999-01-01'
order by growth
|
#SQL23
对所有员工的薪水按照salary降序进行1-N的排名
有一个薪水表salaries简况如下:
对所有员工的薪水按照salary降序进行1-N的排名,要求相同salary并列且按照emp_no升序排列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
-- 方法一:自连接(自表连接,左表一列会连接右表所有列,同SQL18)
select s1.emp_no
,s1.salary
,count(distinct s2.salary) t_rank -- 被筛s2有几个,代表第几大
from salaries s1,salaries s2
where s1.salary <= s2.salary -- 晒出比s1大的s2的salary列
group by 1
order by s1.salary desc,emp_no
-- 方法二:窗口函数
select emp_no
,salary
,dense_rank()over(order by salary desc) t_rank -- 注意要用dense_rank
from salaries
order by t_rank,emp_no
|
这题其实与SQL17、SQL18差不多,后者要求筛选第xx的行,其实解题方法中就包括本题的要求——对其进行排序。这也体现了窗口函数的简便。
#SQL24
获取所有非manager员工当前的薪水情况
有一个员工employees表简况如下:
有一个,部门员工关系表dept_emp简况如下:
有一个部门领导表dept_manager简况如下:
有一个薪水表salaries简况如下:
获取所有非manager员工薪水情况,给出dept_no、emp_no以及salary
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
-- 方法一:排除非manager的员工即可
select d.dept_no
,e.emp_no
,s.salary
from employees e
join dept_emp d
on e.emp_no = d.emp_no
join salaries s
on e.emp_no = s.emp_no
where e.emp_no not in (
select emp_no from dept_manager
)
-- 方法二(不需要employees,因为dept_manager除去manager就是其他员工了)
select d.dept_no
,d.emp_no
,s.salary
from dept_emp d
join salaries s
on d.emp_no = s.emp_no
where d.emp_no not in (
select emp_no from dept_manager
)
|
所以这题可以看出,当表多了之后,理清表的逻辑关系才是关键,例如给出5张表,实际解决问题可能只需要2张表连起来。
#SQL25
获取员工其当前的薪水比其manager当前薪水还高的相关信息
有一个,部门员工关系表dept_emp简况如下:
有一个部门领导表dept_manager简况如下:
有一个薪水表salaries简况如下:
获取员工其当前的薪水比其manager当前薪水还高的相关信息,
第一列给出员工的emp_no,
第二列给出其manager的manager_no,
第三列给出该员工当前的薪水emp_salary,
第四列给该员工对应的manager当前的薪水manager_salary
1
2
3
4
5
6
7
8
9
10
11
12
13
|
select d.emp_no
,m.emp_no manager_no
,s1.salary emp_salary
,s2.salary manager_salary
from dept_emp d
join dept_manager m
on d.dept_no = m.dept_no
and d.emp_no != m.emp_no -- 排除d.emp_no=m.emp_no的对应的正是普通员工与其经理
join salaries s1 -- 于是这里对应的是普通员工的薪水
on d.emp_no = s1.emp_no
join salaries s2
on m.emp_no = s2.emp_no -- 于是这里对应经理的薪水
where s1.salary > s2.salary -- 普通员工比经理薪水高的情况
|
这题dept_emp表和dept_manager表都有emp_no和dept_no字段,不能选错连接字段,此处需要找出的是员工对应的领导,所以应该用员工表的部门id与领导表的部分id配对,这样就得到了员工与其所在部门的领导的对应关系了。由于领导本身也在员工表里,则相同emp_no的就是领导了。
#SQL28
查找描述信息中包含robot的电影对应的分类名称以及电影数目,而且还需要该分类对应电影数量>=5部(注意,此题已被牛客网删除,可能是因为此题比较鸡肋的缘故)
film表
| 字段 |
说明 |
| film_id |
电影id |
| title |
电影名称 |
| description |
电影描述信息 |
1
2
3
4
5
6
7
8
9
|
CREATE TABLE IF NOT EXISTS film (
film_id smallint(5) NOT NULL DEFAULT '0',
title varchar(255) NOT NULL,
description text,
PRIMARY KEY (film_id));
|
category表
| 字段 |
说明 |
| category_id |
电影分类id |
| name |
电影分类名称 |
| last_update |
电影分类最后更新时间 |
1
2
3
4
5
6
7
8
9
|
CREATE TABLE category (
category_id tinyint(3) NOT NULL,
name varchar(25) NOT NULL,
last_update timestamp,
PRIMARY KEY ( category_id ));
|
film_category表
| 字段 |
说明 |
| film_id |
电影id |
| category_id |
电影分类id |
| last_update |
电影id和分类id对应关系的最后更新时间 |
1
2
3
4
5
6
7
|
CREATE TABLE film_category (
film_id smallint(5) NOT NULL,
category_id tinyint(3) NOT NULL,
last_update timestamp);
|
查找描述信息(film.description)中包含robot的电影对应的分类名称(category.name)以及电影数目(count(film.film_id)),而且还需要该分类包含电影总数量(count(film_category.category_id))>=5部
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
select name
,count(fc.film_id) num
from film_category fc
join category c
on fc.category_id =c.category_id
join film f
on fc.film_id = f.film_id
where description like '%robot%'
and fc.category_id in -- 该分类包含电影总数量>=5部
(
select category_id
from film_category
group by 1
having count(film_id) >= 5
)
group by 1
|
这题特别需要注意的就是该分类包含电影总数量>=5,不是包含robot的电影>=5,因此这题必须分步骤,不能一气呵成。
#SQL35
批量插入数据,不使用replace操作
题目已经先执行了如下语句:
1
2
3
4
5
6
7
8
9
|
drop table if exists actor;
create table actor
(
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update DATETIME NOT NULL
);
insert into actor values ('3', 'WD', 'GUINESS', '2006-02-15 12:34:33');
|
对于表actor插入如下数据,如果数据已经存在,请忽略(不支持使用replace操作)
| actor_id |
first_name |
last_name |
last_update |
| '3' |
'ED' |
'CHASE' |
'2006-02-15 12:34:33' |
1
2
|
-- 如果存在,则忽略 insert ignore(mysql写法)
INSERT IGNORE INTO actor VALUES('3','ED','CHASE','2006-02-15 12:34:33');
|
本题我做了两遍,第二遍隐约记得有个ignore,然后先把ignore放insert前失败了,第二次放insert后成功了。
#SQL46
在audit表上创建外键约束,其emp_no对应employees_test表的主键id
在audit表上创建外键约束,其emp_no对应employees_test表的主键id。
(以下2个表已经创建了)
1
2
3
4
5
6
7
8
9
10
11
12
|
CREATE TABLE employees_test(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
CREATE TABLE audit(
EMP_no INT NOT NULL,
create_date datetime NOT NULL
);
|
1
2
3
4
5
6
7
|
-- 这是属于SQL高级特征-对字段进行约束的内容了,对外键进行约束的语法为:
-- ALTER TABLE <表名>
-- ADD CONSTRAINT FOREIGN KEY (<作为外键的列名>)
-- REFERENCES <关联的表>(<关联的列>)
ALTER TABLE audit
ADD CONSTRAINT FOREIGN KEY (emp_no)
REFERENCES employees_test(id)
|
这题我做第二遍时,依然不记得怎么写,只记得有constraint和references,最后试错了几次居然通过,代码如下:
1
2
|
alter table audit add constraint fk_audit_employees
foreign key audit(emp_no) references employees_test(id);
|
第一个表名可省略。
对外键进行约束的语法为:
ALTER TABLE <表名>
ADD CONSTRAINT <约束名> FOREIGN KEY (<作为外键的列名>)
REFERENCES <关联的表>(<关联的列>)
其实CONSTRAINT <约束名> 可以省略。
如果是在刚创建的时候时候语法就是在新的一行上写上这句。例如:
1
2
3
4
5
|
create table audit(
emp_no int not null,
create_date datetime not null,
foreign key(emp_no) references employees_test(id)
);
|
#SQL50
将employees表中的所有员工的last_name和first_name通过引号连接起来
1
2
3
4
5
6
7
8
|
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
|
将employees表中的所有员工的last_name和first_name通过(')连接起来。
1
2
3
4
5
6
7
8
9
10
|
-- 注意 ' 要转义,有两种转义方法
-- 方法一
select concat(last_name,'\'',first_name) from employees;
-- 方法二
select concat(last_name,'''',first_name) from employees;
-- 或者请出双引号
select concat(last_name,"'", first_name) from employees;
|
#SQL51
查找字符串 10,A,B 中逗号,出现的次数cnt
现有strings表如下:
- id指序列号;
- string列中存放的是字符串,且字符串中仅包含数字、字母和逗号类型的字符。
| id |
string |
| 1 |
10,A,B,C,D |
| 2 |
A,B,C,D,E,F |
| 3 |
A,11,B,C,D,E,G |
请你统计每个字符串中逗号出现的次数cnt。
以上例子的输出结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
-- 方法一:把逗号去除后计算长度减少了多少
select id,length(string)-length(replace(string,',','')) from strings;
-- replace(字符串,“需要替换的子串”,“用于替换子串的字符串”)
-- 方法二:把数字字母去除后计算长度
SELECT
id,
length(
regexp_replace(STRING, '[A-Z0-9]', '')
)
FROM
strings;
|
这题做第二遍依然不会。
#SQL52
获取Employees中的first_name
现有employees表如下:
| emp_no |
birth_date |
first_name |
last_name |
gender |
hire_date |
| 10001 |
1953-09-02 |
Georgi |
Facello |
M |
1986-06-26 |
| 10002 |
1964-06-02 |
Bezalel |
Simmel |
F |
1985-11-21 |
| 10003 |
1959-12-03 |
Parto |
Bamford |
M |
1986-08-28 |
| 10004 |
1954-05-01 |
Christian |
Koblick |
M |
1986-12-01 |
| 10005 |
1955-01-21 |
Kyoichi |
Maliniak |
M |
1989-09-12 |
| 10006 |
1953-04-20 |
Anneke |
Preusig |
F |
1989-06-02 |
| 10007 |
1957-05-23 |
Tzvetan |
Zielinski |
F |
1989-02-10 |
| 10008 |
1958-02-19 |
Saniya |
Kalloufi |
M |
1994-09-15 |
| 10009 |
1952-04-19 |
Sumant |
Peac |
F |
1985-02-18 |
| 10010 |
1963-06-01 |
Duangkaew |
Piveteau |
F |
1989-08-24 |
| 10011 |
1953-11-07 |
Mary |
Sluis |
F |
1990-01-22 |
请你将employees中的first_name按照first_name最后两个字母升序进行输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
-- SUBSTR( )与SUBSTRING( )意思相等,第一个字符的位置为都1
-- 方法一
select first_name
from employees
order by right(first_name,2)
-- 方法二
select first_name
from employees
order by substring(first_name,-2) -- 为负数,返回从倒数第2个位置到字符串结尾的子字符串
-- 注意,如果第三个参数省略,则直接截取到末尾
-- 方法三
select first_name
from employees
order by substring(first_name,length(first_name)-1)
|
#SQL53
按照dept_no进行汇总
按照dept_no进行汇总,属于同一个部门的emp_no按照逗号进行连接,结果给出dept_no以及连接出的结果employees。
表格结构如下:
1
2
3
4
5
6
|
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
|
1
2
3
4
5
6
7
8
9
10
11
|
-- 利用group_concat函数
select dept_no
,group_concat(emp_no) employees
from dept_emp
group by dept_no
-- 或者这样。合并的字段分隔符默认为逗号,可通过参数separator指定
select dept_no
,group_concat(emp_no separator ',') employees
from dept_emp
group by dept_no
|
第二次做时忘了group_concat的分隔符默认是逗号,而且忘记参数这里seperator不要加逗号。
group_concat(X,Y)
group_concat()函数返回X的非null值的连接后的字符串。如果给出了参数Y,将会在每个X之间用Y作为分隔符。如果省略了Y,“,”将作为默认的分隔符。每个元素连接的顺序是随机的。(注意,MySQL 的格式不一样)
#SQL57
使用含有关键字exists查找未分配具体部门的员工的所有信息
使用含有关键字exists查找未分配具体部门的员工的所有信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
|
1
2
3
4
5
6
7
8
9
10
|
-- exists意思是存在,逐条比对返回满足条件的
select * from employees e
where not exists (
select d.dept_no from dept_emp d
where d.emp_no = e.emp_no);
-- 如果填的是exists,且后面匹配成功了,就是有部门的员工,加个not就是没有部门的员工
-- 换句话说,本题意为在 employees 中挑选出令
-- select d.dept_no from dept_emp d where d.emp_no = e.emp_no不成立的记录
|
exists强调是否返回结果集,不要求知道返回什么。只要返回了字段,就是真。
【第二次做,磕磕碰碰才做出来】
#SQL60
统计salary的累计和running_total
按照salary的累计和running_total,其中running_total为前N个当前( to_date = '9999-01-01')员工的salary累计和,其他以此类推。 具体结果如下Demo展示。
1
2
3
4
5
|
CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
|
输出格式:
| emp_no |
salary |
running_total |
| 10001 |
88958 |
88958 |
| 10002 |
72527 |
161485 |
| 10003 |
43311 |
204796 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
-- 方法一:子查询法
select s1.emp_no
,s1.salary
,
(
select sum(s2.salary) from salaries s2
where s2.emp_no <= s1.emp_no -- 把小于等于的都加起来就是了
and s2.to_date = '9999-01-01'
) running_total
from salaries s1
where s1.to_date = '9999-01-01'
order by s1.emp_no
-- 方法二:自连接法
select s1.emp_no
,s1.salary
,sum(s2.salary) running_total
from salaries s1
join salaries s2
on s1.emp_no >= s2.emp_no
where s1.to_date = '9999-01-01'
and s2.to_date = '9999-01-01'
group by s1.emp_no
order by s1.emp_no
-- 方法三:窗口函数
select emp_no
,salary
,sum(salary)over(order by emp_no) running_total
from salaries
where to_date = '9999-01-01'
|
此题是SQL23的变种,即按照emp_no排序后进行累加,对于自连接法只需要将连接后对应小于它的emp_no的salary相加,对于窗口函数,只需要将排序函数变成求和函数即可。
第二次做窗口函数直接秒杀。
#SQL61
对于employees表中,给出奇数行的first_name
对于employees表中,输出first_name排名(按first_name升序排序)为奇数的first_name
1
2
3
4
5
6
7
8
9
|
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
|
如,输入为:
1
2
3
4
|
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
|
输出格式:
因为Georgi按first_name排名为3,Anneke按first_name排名为1,所以会输出这2个,且输出时不需排序。
请你在不打乱原序列顺序的情况下,输出:按first_name排升序后,取奇数行的first_name。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
-- 方法一:自连接法类似
select e1.first_name
from employees e1
where (
select count(*) -- 得到的结果是e1.first_name该行值的实际排名
from employees e2
where e1.first_name >= e2.first_name
)%2 = 1
-- 方法二:窗口函数法
-- (不行,可能会打乱原顺序,除非原表是按emp_no升序排列的)
# select first_name
# from
# (
# select emp_no
# ,first_name
# ,row_number()over(order by first_name) r
# from employees
# ) a
# where r%2 = 1
# order by emp_no
-- 修正版窗口函数
SELECT
e.first_name
FROM employees e JOIN
(
SELECT
first_name
, ROW_NUMBER() OVER(ORDER BY first_name ASC) AS r_num
FROM employees
) AS t
ON e.first_name = t.first_name
WHERE t.r_num % 2 = 1;
-- 这里用原表连接窗口函数结果,就不打乱顺序了
|
此题也是SQL23的变种,只不过排序后筛选的是奇数行。至此,SQL16、SQL17、SQL23、SQL60、SQL61实际可以概况为一类题:(分组)排序再选择问题。
#SQL65
异常的邮件概率
现在有一个需求,让你统计正常用户发送给正常用户邮件失败的概率:
有一个邮件(email)表,id为主键, type是枚举类型,枚举成员为(completed,no_completed),completed代表邮件发送是成功的,no_completed代表邮件是发送失败的。简况如下:
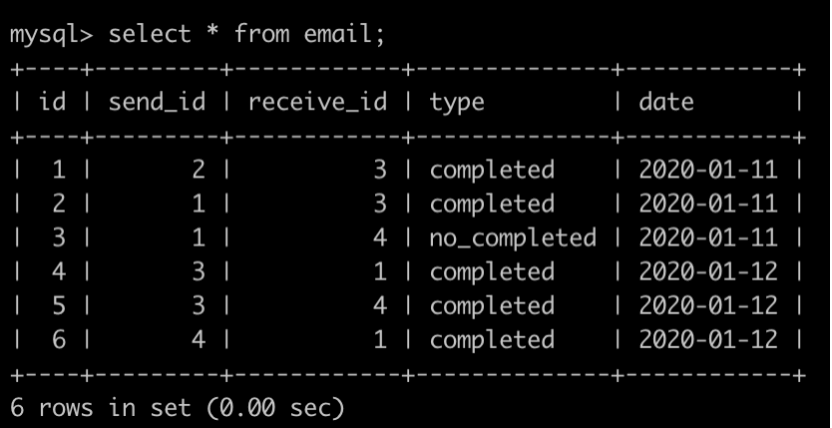
第1行表示为id为2的用户在2020-01-11成功发送了一封邮件给了id为3的用户;
...
第3行表示为id为1的用户在2020-01-11没有成功发送一封邮件给了id为4的用户;
...
第6行表示为id为4的用户在2020-01-12成功发送了一封邮件给了id为1的用户;
下面是一个用户(user)表,id为主键,is_blacklist为0代表为正常用户,is_blacklist为1代表为黑名单用户,简况如下:
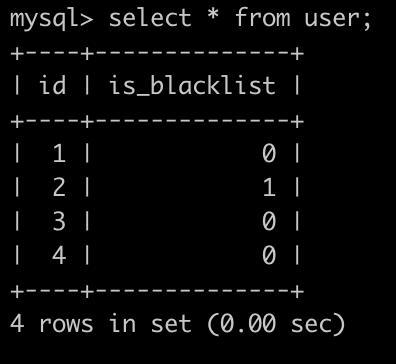
第1行表示id为1的是正常用户;
第2行表示id为2的不是正常用户,是黑名单用户,如果发送大量邮件或者出现各种情况就会容易发送邮件失败的用户
。。。
第4行表示id为4的是正常用户
现在让你写一个sql查询,每一个日期里面,正常用户发送给正常用户邮件失败的概率是多少,结果保留到小数点后面3位(3位之后的四舍五入),并且按照日期升序排序,上面例子查询结果如下:
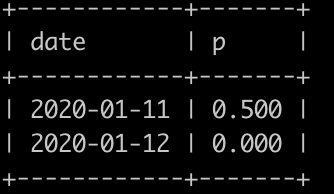
结果表示:
2020-01-11失败的概率为0.500,因为email的第1条数据,发送的用户id为2是黑名单用户,所以不计入统计,正常用户发正常用户总共2次,但是失败了1次,所以概率是0.500;
2020-01-12没有失败的情况,所以概率为0.000.
这题要注意send_id与receive_id都要判断是否为黑名单,因为求的是正常用户发送给正常用户邮件失败的概率是多少。
1
2
3
4
5
6
7
8
9
10
11
12
|
-- 利用group by与case when的组合拳
select date
,round(sum(case type when 'no_completed' then 1 else 0 end) / count(*),3) p
from email e
join user u1
on e.send_id = u1.id
and u1.is_blacklist = 0
join user u2
on e.receive_id = u2.id
and u2.is_blacklist = 0
group by date
order by date
|
#SQL67-71
牛客每天有很多人登录,有一个登录(login)记录表,简况如下:
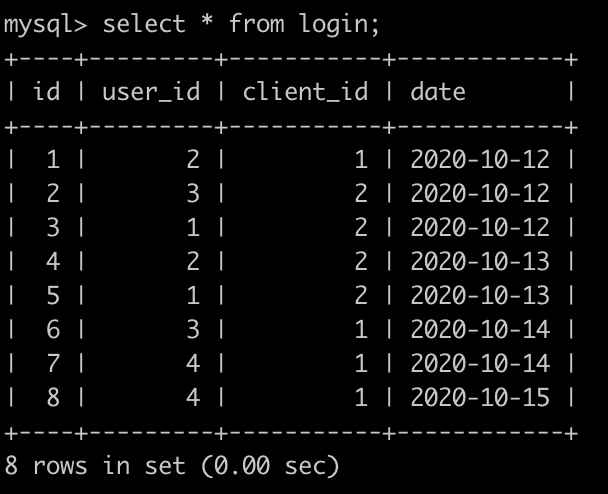
第1行表示user_id为2的用户在2020-10-12使用了客户端id为1的设备登录了牛客网,因为是第1次登录,所以是新用户
。。。
第4行表示user_id为2的用户在2020-10-13使用了客户端id为2的设备登录了牛客网,因为是第2次登录,所以是老用户
。。
最后1行表示user_id为4的用户在2020-10-15使用了客户端id为1的设备登录了牛客网,因为是第2次登录,所以是老用户
有一个刷题(passing_number)表,简况如下:
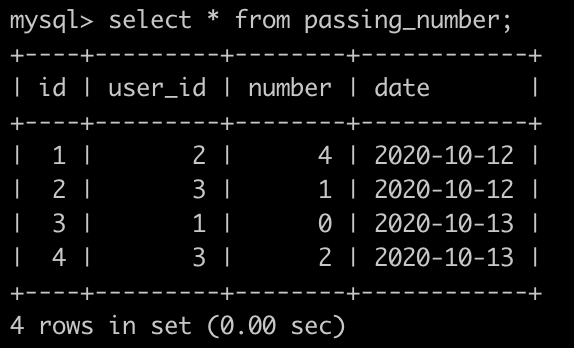
第1行表示user_id为2的用户在2020-10-12通过了4个题目。
。。。
第3行表示user_id为1的用户在2020-10-13提交了代码但是没有通过任何题目。
第4行表示user_id为4的用户在2020-10-13通过了2个题目
还有一个用户(user)表,简况如下:
还有一个客户端(client)表,简况如下:
问题:
SQL67 牛客每个人最近的登录日期(二)
请你写出一个sql语句查询每个用户最近一天登录的日子,用户的名字,以及用户用的设备的名字,并且查询结果按照user的name升序排序
SQL68 牛客每个人最近的登录日期(三)
请你写出一个sql语句查询新登录用户次日成功的留存率,即第1天登陆之后,第2天再次登陆的概率,保存小数点后面3位(3位之后的四舍五入)
SQL69 牛客每个人最近的登录日期(四)
请你写出一个sql语句查询每个日期登录新用户个数,并且查询结果按照日期升序排序
SQL70 牛客每个人最近的登录日期(五)
请你写出一个sql语句查询每个日期新用户的次日留存率,结果保留小数点后面3位数(3位之后的四舍五入),并且查询结果按照日期升序排序
SQL71 牛客每个人最近的登录日期(六)
请你写出一个sql语句查询刷题信息,包括: 用户的名字,以及截止到某天,累计总共通过了多少题,并且查询结果先按照日期升序排序,再按照姓名升序排序,有登录却没有刷题的那一天的数据不需要输出
解析:
SQL67
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
-- 方法一:先查出最近登录对应的用户信息,然后把额外信息连过去
select u.name u_n
,c.name c_n
,l.date date
from login l
join
(
select user_id
,max(date) d
from login
group by 1
) a -- 用户最近登录表
on l.user_id = a.user_id
and l.date = a.d
join client c
on l.client_id = c.id
join user u
on l.user_id = u.id
order by u_n
-- 方法一.一:这种是方法一的改良,实际上,
-- 同一用户的客户端client.name相同,所以对user.name分组后没有影响结果,
-- 即便是非聚合字段也没事(group by默认取非聚合字段的第一条,这只有一条)
-- 由于在标准语法中select子句中不能出现group by子句中未出现的列名,
-- 这个在标准语法要求中通不过
select u.name u_n
,c.name c_n
,max(date)
from user u
join login l
on u.id = l.user_id
join client c
on l.client_id = c.id
group by u.name
order by u.name
-- 方法二:联结查询
select u.name,c.name,l1.date
from login l1,user u,client c
where l1.date=(select max(l2.date) from login l2 where l1.user_id=l2.user_id)
and l1.user_id=u.id
and l1.client_id=c.id
order by u.name
-- 方法三:窗口函数,全表联结,然后用窗口函数选个排第一的
select u_n
,c_n
,date
from
(
select b.name u_n
,c.name c_n
,date
,rank()over(partition by b.name order by date desc) r
from login a
join user b
on a.user_id = b.id
join client c
on a.client_id = c.id
) a
where r = 1
|
SQL68
分析:
这题求的概率p=新登录且次数登录的用户数/全部用户数,关键是求登录日期最小的登录日期比次小的小一天就是次日登录过的用户数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
-- 方法一:表连接
select round(count(*)/(select count(distinct user_id) from login),3) p
from login l
join
(
select user_id
,min(date) first_date -- 最小的登录日期
from login
group by user_id
) f
on l.user_id = f.user_id
where date = DATE_ADD(f.first_date,INTERVAL 1 DAY) -- 筛出比最小的大一天的记录
-- 方法二:表连接(稍微修改)
select round(count(l.id)/count(f.user_id),3) p
from login l
right join -- 各唯一用户id及最小登录日期表作为主表
(
select user_id
,min(date) first_date
from login
group by user_id
) f
on l.user_id = f.user_id
and l.date = DATE_ADD(f.first_date,INTERVAL 1 DAY)
-- 用right join将各唯一用户id及最小登录日期表作为主表,
-- round部分就不用进行更多子查询了,l.id数量即满足条件用户,f.user_id即全部用户
-- 方法三:子查询
select round(count(*)/(select count(distinct user_id) from login),3) p
from login l
where (user_id,date) in (
select user_id
,DATE_ADD(min(date),INTERVAL 1 DAY)
from login
group by user_id
)
|
第二次做反而不会了,这样做的,还没验证对不对:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
select
round(count(if(datediff(a_date,b_date)=1,c.user_id,null))/count(*),3) p
from
(
select a.user_id
,a.date a_date
,b.date b_date
,row_number()over(partition by a.user_id order by a.date,b.date) r
from
(
select user_id
,date
from login
group by user_id,date
) a
join a as b
on a.user_id=b.user_id
and a.date<b.date
) c
where c.r=1
|
SQL69
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
-- 方法一:先获得各唯一用户id及最小登录日期表,
-- 与原表匹配,各最小登录日期有几个,该日期就有几个用户登录了,
-- 为了得到登录用户数为0的日期,用left join保留所有date
select date
,count(first_date) new
from login l
left join
(
select
user_id
,min(date) first_date
from login
group by user_id
) a
on l.user_id = a.user_id
and l.date = a.first_date
group by date
-- 方法二:窗口函数,排序后数下各日期有几个number one就可以
select date
,sum(case when r = 1 then 1 else 0 end)
from
(
select *
,rank()over(partition by user_id order by date) r
from login
) a
group by date
order by date
-- 方法三:联结查询机灵法
-- 对各date,满足case when中条件计数板就加1,外层用group by汇总计数板
select date,sum(t) from
(
select date
,case when (user_id,date) in
(select user_id,min(date) from login group by user_id)
then 1
else 0
end as t
from login
) a
group by date
order by date
|
SQL70
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
-- 方法一
SELECT a.date, ROUND(COUNT(b.user_id) * 1.0/COUNT(a.user_id), 3) AS p
FROM (
SELECT user_id, MIN(date) AS date
FROM login
GROUP BY user_id) a
LEFT JOIN login b
ON a.user_id = b.user_id
AND b.date = date(a.date, '+1 day')
GROUP BY a.date
UNION
SELECT date, 0.000 AS p
FROM login
WHERE date NOT IN (
SELECT MIN(date)
FROM login
GROUP BY user_id)
ORDER BY date;
-- 方法二(尚未验证)
sele
,c.user_id
round(count(if(datediff(a_date,b_date)=1,c.user_id,null))/count(*),3) p
from
(
select a.user_id
,a.date a_date
,b.date b_date
,row_number()over(partition by a.user_id order by a.date,b.date) r
from
(
select user_id
,date
from login
group by user_id,date
) a
join a as b
on a.user_id=b.user_id
and a.date<b.date
) c
where c.r=1
group by c.user_id
|
SQL71
1
2
3
4
5
6
7
8
9
10
|
select u.name u_n
,l.date
,sum(p.number)over(partition by u.name order by l.date)
from login l
join passing_number p
on l.user_id = p.user_id
and l.date = p.date
join user u
on l.user_id = u.id
order by 2,1
|
#SQL75-76
牛客每次考试完,都会有一个成绩表(grade),如下:
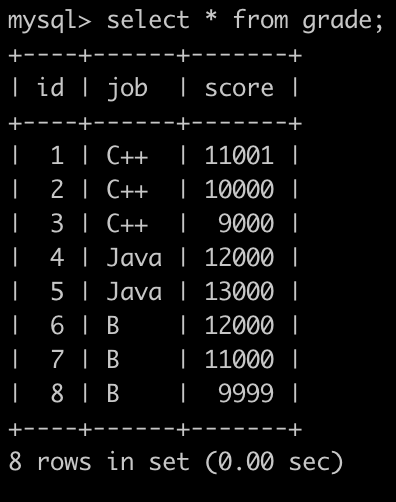
第1行表示用户id为1的用户选择了C++岗位并且考了11001分
。。。
第8行表示用户id为8的用户选择了B语言岗位并且考了9999分
问题:
SQL75 考试分数(四)
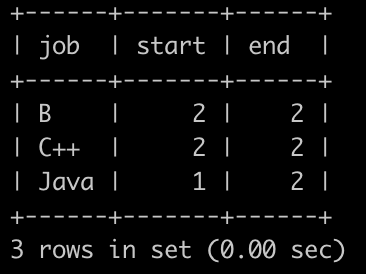
请你写一个sql语句查询各个岗位分数升序排列之后的中位数位置的范围,并且按job升序排序,结果如下:
SQL76 考试分数(五)
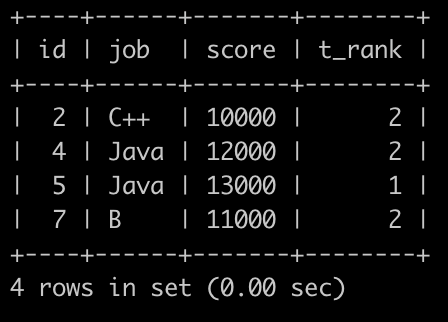
请你写一个sql语句查询各个岗位分数的中位数位置上的所有grade信息,并且按id升序排序,结果如下:
解析:
SQL75
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
-- 方法一
select job
,round(case when s%2=0 then s/2 else (s+1)/2 end,0) start
,round(case when s%2=0 then s/2+1 else (s+1)/2 end,0) end
from
(
select job
,count(*) s
from grade
group by job
) a
order by job
-- 方法二(简化)
-- 偶数的round(s/2)与奇数的round(s/2)对算开头是一样的 round(4/2)=2 round(5/2)=3
-- 偶数的round((s+1)/2与奇数的round(s+1)/2对算结尾是一样的 round(4+1/2)=3 round(5+1)/2=3
select job
,round(round(s/2)) start
,round(round(s+1)/2) end
from
(
select job
,count(*) s
from grade
group by job
) a
order by job
|
SQL76
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
-- 方法一:我的普通思路
select id
,job
,score
,t_rank
from
(
select g.id
,g.job
,g.score
,rank()over(partition by g.job order by g.score desc) t_rank
,start
,end
from grade g
join
(
select job
,round(case when s%2=0 then s/2 else (s+1)/2 end,0) start
,round(case when s%2=0 then s/2+1 else (s+1)/2 end,0) end
from
(
select job
,count(*) s
from grade
group by job
) a
) b
on g.job = b.job
) c
where t_rank in (start,end)
order by id
-- 方法二:大佬妙解
select id
,job
,score
,s_rank
from
(select *
,(row_number()over(partition by job order by score desc))as s_rank
,(count(score)over(partition by job))as num
from grade) t1
where abs(t1.s_rank - (t1.num+1)/2) < 1 -- 无论奇偶,中位数的位置距离(个数+1)/2 小于1
order by id
|
#SQL79-81
有很多同学在牛客购买课程来学习,购买会产生订单存到数据库里。
有一个订单信息表(order_info),简况如下:
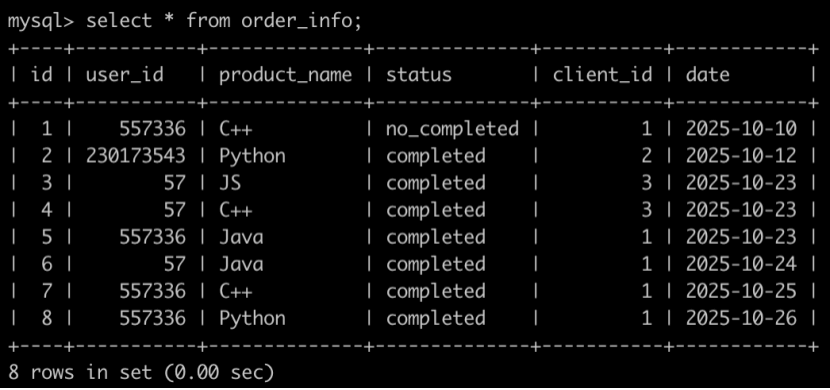
第1行表示user_id为557336的用户在2025-10-10的时候使用了client_id为1的客户端下了C++课程的订单,但是状态为没有购买成功。
第2行表示user_id为230173543的用户在2025-10-12的时候使用了client_id为2的客户端下了Python课程的订单,状态为购买成功。
问题:
SQL79 牛客的课程订单分析(三)
请你写出一个sql语句查询在2025-10-15以后,同一个用户下单2个以及2个以上状态为购买成功的C++课程或Java课程或Python课程的订单信息,并且按照order_info的id升序排序
SQL80 牛客的课程订单分析(四)
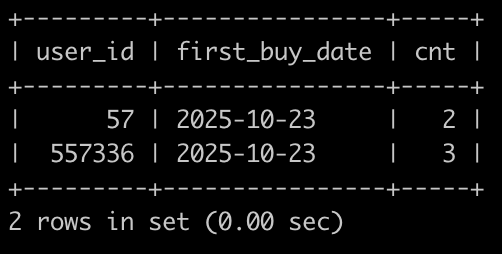
请你写出一个sql语句查询在2025-10-15以后,如果有一个用户下单2个以及2个以上状态为购买成功的C++课程或Java课程或Python课程,那么输出这个用户的user_id,以及满足前面条件的第一次购买成功的C++课程或Java课程或Python课程的日期first_buy_date,以及购买成功的C++课程或Java课程或Python课程的次数cnt,并且输出结果按照user_id升序排序,以上例子查询结果如下:
SQL81 牛客的课程订单分析(五)
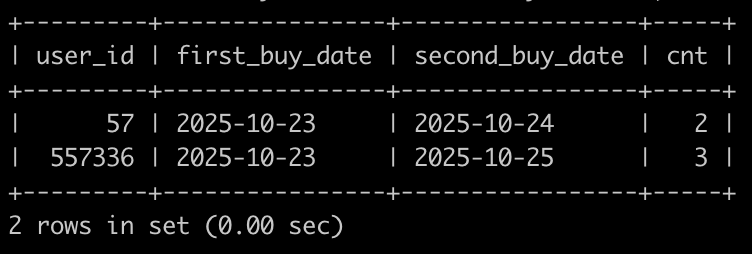
请你写出一个sql语句查询在2025-10-15以后,如果有一个用户下单2个以及2个以上状态为购买成功的C++课程或Java课程或Python课程,那么输出这个用户的user_id,以及满足前面条件的第一次购买成功的C++课程或Java课程或Python课程的日期first_buy_date,以及满足前面条件的第二次购买成功的C++课程或Java课程或Python课程的日期second_buy_date,以及购买成功的C++课程或Java课程或Python课程的次数cnt,并且输出结果按照user_id升序排序,以上例子查询结果如下:
解析:
SQL79
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
-- 方法一:普通法
select * from
order_info
where user_id in
(
select user_id
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
group by user_id
having count(status) >= 2
)
and status = 'completed'
and product_name in ('C++','Java','Python')
and date > '2025-10-15'
order by id
-- 方法二:窗口函数
select id
,user_id
,product_name
,status
,client_id
,date
from
(
select *
,count(*)over(partition by user_id) cnt
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
) a
where cnt >= 2
order by id
|
#SQL82-83
有很多同学在牛客购买课程来学习,购买会产生订单存到数据库里。
有一个订单信息表(order_info),简况如下:
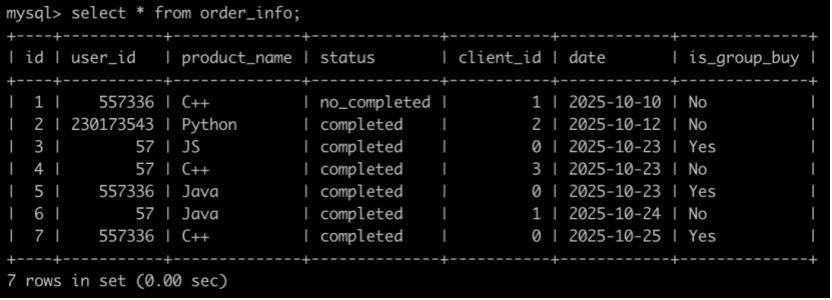
第1行表示user_id为557336的用户在2025-10-10的时候使用了client_id为1的客户端下了C++课程的非拼团(is_group_buy为No)订单,但是状态为没有购买成功。
第2行表示user_id为230173543的用户在2025-10-12的时候使用了client_id为2的客户端下了Python课程的非拼团(is_group_buy为No)订单,状态为购买成功。
。。。
最后1行表示user_id为557336的用户在2025-10-25的时候使用了下了C++课程的拼团(is_group_buy为Yes)订单,拼团不统计客户端,所以client_id所以为0,状态为购买成功。
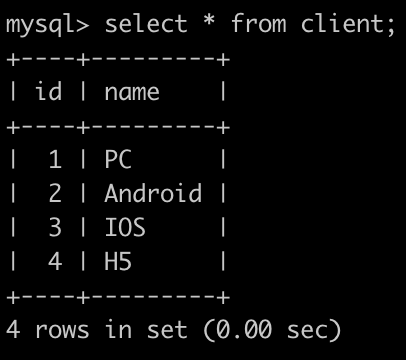
有一个客户端表(client),简况如下:
问题:
SQL82 牛客的课程订单分析(六)
请你写出一个sql语句查询在2025-10-15以后,同一个用户下单2个以及2个以上状态为购买成功的C++课程或Java课程或Python课程的订单id,是否拼团以及客户端名字信息,最后一列如果是非拼团订单,则显示对应客户端名字,如果是拼团订单,则显示NULL,并且按照order_info的id升序排序,以上例子查询结果如下:
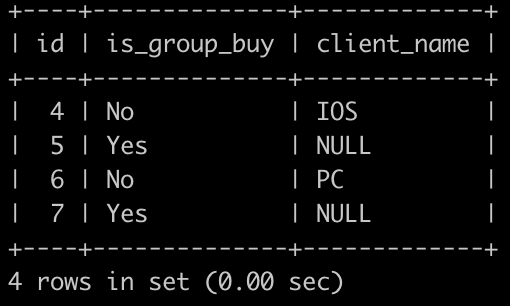
SQL83 牛客的课程订单分析(七)
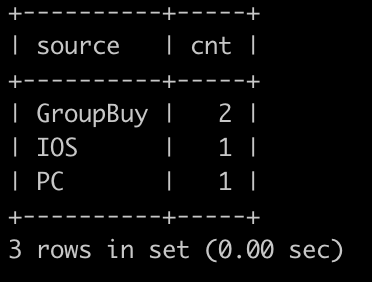
请你写出一个sql语句查询在2025-10-15以后,同一个用户下单2个以及2个以上状态为购买成功的C++课程或Java课程或Python课程的来源信息,第一列是显示的是客户端名字,如果是拼团订单则显示GroupBuy,第二列显示这个客户端(或者是拼团订单)有多少订单,最后结果按照第一列(source)升序排序,以上例子查询结果如下:
解析:
SQL82
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
-- 方法一:初始笨拙法
select o.id
,is_group_buy
,case when is_group_buy = 'Yes' then 'None'
when is_group_buy='No' then name end client_name
from order_info o
left join client c -- 这题要left join
on o.client_id = c.id
where date > '2025-10-15'
and status = 'completed'
and product_name IN ('C++','Java','Python')
and user_id IN
(
select user_id
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name IN ('C++','Java','Python')
group by user_id
having count(status) >= 2
)
order by o.id
-- 方法二:由于使用左连接不需要用case when
select o.id
,is_group_buy
,name client_name
from order_info o
left join client c -- 这题要left join
on o.client_id = c.id
where date > '2025-10-15'
and status = 'completed'
and product_name IN ('C++','Java','Python')
and user_id IN
(
select user_id
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name IN ('C++','Java','Python')
group by user_id
having count(status) >= 2
)
order by o.id
-- 方法三:用窗口函数进一步简化
select a.id
,is_group_buy
,name client_name
from
(
select *
,count(*)over(partition by user_id) cnt
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name IN ('C++','Java','Python')
) a
left join client c -- 这题要left join
on a.client_id = c.id
where cnt >= 2
order by a.id
|
SQL83
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
-- 方法一:初始笨拙法
select COALESCE(source,'GroupBuy')
,count(*) cnt
from
(
select o.id
,name source
from order_info o
left join client c
on o.client_id = c.id
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
and user_id IN
(
select user_id
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
group by 1
having count(status) >= 2
)
) a
group by 1
order by 1
-- 方法二:窗口函数简化版
select COALESCE(name,'GroupBuy')
,count(*) cnt
from
(
select *
,count(*)over(partition by user_id) num
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
) a
left join client c
on a.client_id = c.id
where num >= 2
group by 1
order by 1
|
#SQL86
实习广场投递简历分析(三)
在牛客实习广场有很多公司开放职位给同学们投递,同学投递完就会把简历信息存到数据库里。
现在有简历信息表(resume_info),部分信息简况如下:
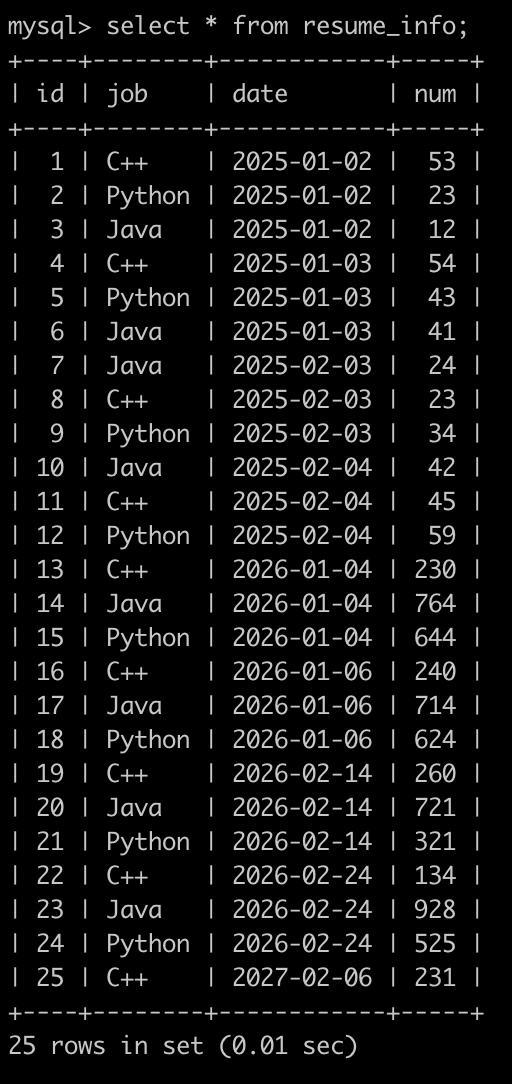
第1行表示,在2025年1月2号,C++岗位收到了53封简历
。。。
最后1行表示,在2027年2月6号,C++岗位收到了231封简历
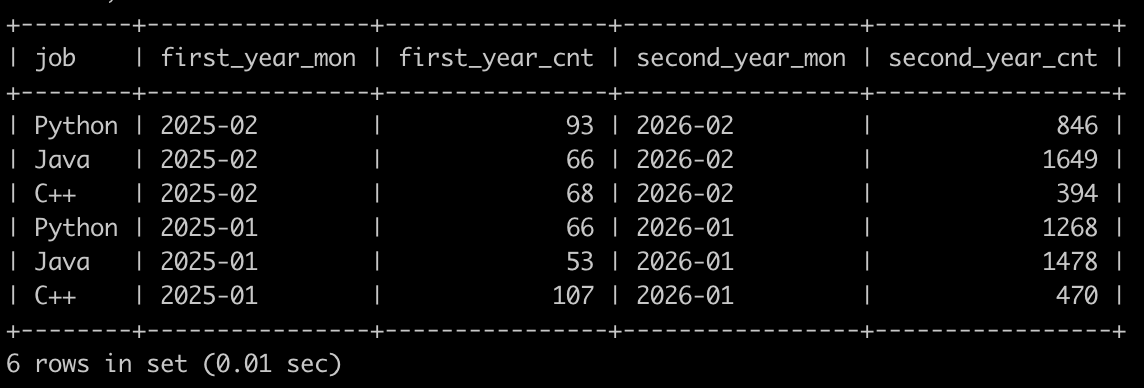
请你写出SQL语句查询在2025年投递简历的每个岗位,每一个月内收到简历的数目,和对应的2026年的同一个月同岗位,收到简历的数目,最后的结果先按first_year_mon月份降序,再按job降序排序显示,以上例子查询结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
-- 思路都是筛选2025年各岗位每月做临时表a,2026年各岗位每月做临时表b,再进行连接
-- 我的看似复杂,其实结构也是这个
select a.job
,first_year_mon
,first_year_cnt
,second_year_mon
,second_year_cnt
from
(
select job
,substring(date,1,7) first_year_mon
,substring(date,6,2) first_mon
,sum(num) first_year_cnt
from resume_info r1
where substring(date,1,4) = '2025'
group by 1,2,3
) a
join
(
select job
,substring(date,1,7) second_year_mon
,substring(date,6,2) second_mon
,sum(num) second_year_cnt
from resume_info r2
where substring(date,1,4) = '2026'
group by 1,2,3
) b
on a.job = b.job
and a.first_mon = b.second_mon
order by first_year_mon desc,a.job desc
|
#SQL88
SQL88 最差是第几名(二)
TM小哥和FH小妹在牛客大学若干年后成立了牛客SQL班,班的每个人的综合成绩用A,B,C,D,E表示,90分以上都是A,80~90分都是B,60~70分为C,50~60为D,E为50分以下
因为每个名次最多1个人,比如有2个A,那么必定有1个A是第1名,有1个A是第2名(综合成绩同分也会按照某一门的成绩分先后)。
每次SQL考试完之后,老师会将班级成绩表展示给同学看。
现在有班级成绩表(class_grade)如下:
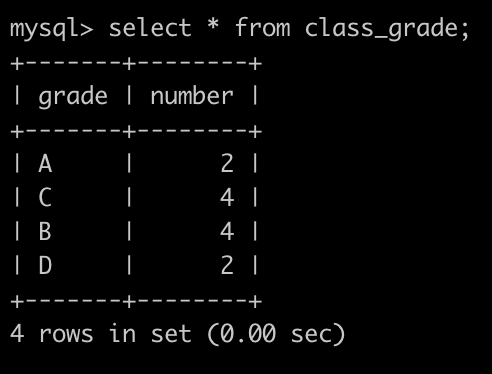
第1行表示成绩为A的学生有2个
.......
最后1行表示成绩为D的学生有2个
老师想知道学生们综合成绩的中位数是什么档位,请你写SQL帮忙查询一下,如果只有1个中位数,输出1个,如果有2个中位数,按grade升序输出,以上例子查询结果如下:
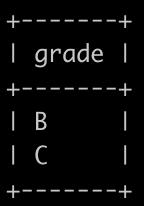
解析:
总体学生成绩排序如下:A, A, B, B, B, B, C, C, C, C, D, D,总共12个数,取中间的2个,取6,7为:B,C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
-- 初始版
select grade
from
(
select grade
,number
,sum(number)over(order by grade) posn1
,sum(number)over(order by grade desc) posn2
from class_grade
) a
where posn1 >= round(case when (select sum(number) from class_grade)%2=0 then (select sum(number) from class_grade)/2 else ((select sum(number) from class_grade)+1)/2 end,0)
and posn2 >= round(case when (select sum(number) from class_grade)%2=0 then (select sum(number) from class_grade)/2 else ((select sum(number) from class_grade)+1)/2 end,0)
order by grade
-- 简化版
select grade
from
(
select grade
,number
,(select sum(number) from class_grade) total
,sum(number)over(order by grade) posn1
,sum(number)over(order by grade desc) posn2
from class_grade
) a
where posn1 >= total/2 and posn2 >= total/2
order by grade
|
#SQL90
SQL90 获得积分最多的人(二)
牛客每天有很多用户刷题,发帖,点赞,点踩等等,这些都会记录相应的积分。
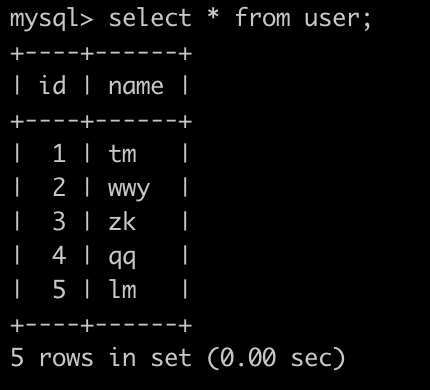
有一个用户表(user),简况如下:
还有一个积分表(grade_info),简况如下:
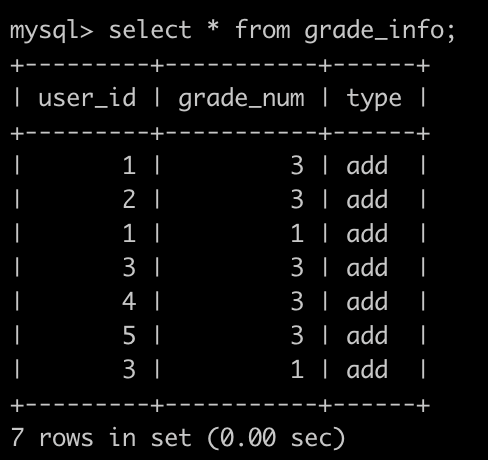
第1行表示,user_id为1的用户积分增加了3分。
第2行表示,user_id为2的用户积分增加了3分。
第3行表示,user_id为1的用户积分又增加了1分。
.......
最后1行表示,user_id为3的用户积分增加了1分。
请你写一个SQL查找积分增加最高的用户的id(可能有多个),名字,以及他的总积分是多少,查询结果按照id升序排序,以上例子查询结果如下:
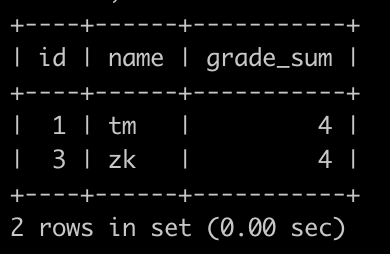
解释:
user_id为1和3的2个人,积分都为4,都要输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
select id
,name
,grade_num
from
(
select *
,dense_rank()over(order by grade_num desc) r
from
(
select u.id
,name
,sum(grade_num) grade_num
from grade_info g
join user u
on g.user_id = u.id
group by 1,2
) a
) b
where r = 1
|
#SQL91
SQL91 获得积分最多的人(三)
牛客每天有很多用户刷题,发帖,点赞,点踩等等,这些都会记录相应的积分。
有一个用户表(user),简况如下:
还有一个积分表(grade_info),简况如下:
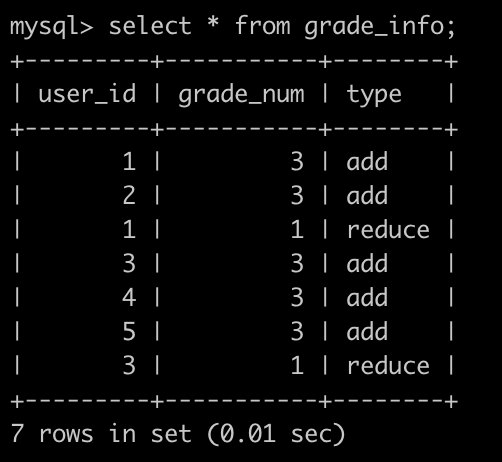
第1行表示,user_id为1的用户积分增加了3分。
第2行表示,user_id为2的用户积分增加了3分。
第3行表示,user_id为1的用户积分减少了1分。
.......
最后1行表示,user_id为3的用户积分减少了1分。
请你写一个SQL查找积分最高的用户的id,名字,以及他的总积分是多少(可能有多个),查询结果按照id升序排序,以上例子查询结果如下:
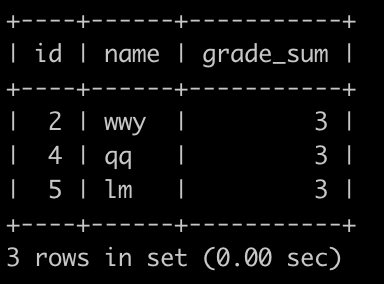
解释:
user_id为1和3的先加了3分,但是后面又减了1分,他们2个是2分,
其他3个都是3分,所以输出其他三个的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
-- 方法一
select id
,name
,grade_sum
from
(
select *
,rank()over(order by grade_sum desc) r
from
(
select u.id
,u.name
,sum(true_grade) grade_sum
from user u
join
(
select *
,case when type='add' then grade_num else -1*grade_num end true_grade
from grade_info
) a
on u.id = a.user_id
group by 1,2
) b
) c
where r = 1
order by 1
-- 方法二:简化版
select id
,name
,grade_sum
from
(
select *
,rank()over(order by grade_sum desc) r
from
(
select u.id
,u.name
,sum(case when type='add' then grade_num else -1*grade_num end) grade_sum
from user u
join grade_info g
on u.id = g.user_id
group by 1,2
) b
) c
where r = 1
order by 1
|