以下对微博上一位大V进行内容爬取与分析。
#数据获取
首先安装Python的微博爬虫包:
1
|
pip install weibo_spider
|
然后在一个目录中初次执行:
会在当前目录下生成config.json配置文件。新建user_id_list.txt文件,按照README.md填写config.json和user_id_list.txt相应参数。
进行相关配置后(用MySQL数据库承接爬取的数据),再次运行
开始爬虫。
#数据概览
该爬虫脚本会在MySQL数据库中新建一个叫做weibo的数据库,并建立两张表,user表和weibo表,分别存放用户信息和内容信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
mysql> use weibo;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+-----------------+
| Tables_in_weibo |
+-----------------+
| user |
| weibo |
+-----------------+
2 rows in set (0.00 sec)
|
user表字段如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
mysql> desc user;
+-----------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+--------------+------+-----+---------+-------+
| id | varchar(20) | NO | PRI | NULL | |
| nickname | varchar(30) | YES | | NULL | |
| gender | varchar(10) | YES | | NULL | |
| location | varchar(200) | YES | | NULL | |
| birthday | varchar(40) | YES | | NULL | |
| description | varchar(400) | YES | | NULL | |
| verified_reason | varchar(140) | YES | | NULL | |
| talent | varchar(200) | YES | | NULL | |
| education | varchar(200) | YES | | NULL | |
| work | varchar(200) | YES | | NULL | |
| weibo_num | int | YES | | NULL | |
| following | int | YES | | NULL | |
| followers | int | YES | | NULL | |
+-----------------+--------------+------+-----+---------+-------+
13 rows in set (0.01 sec)
|
weibo表内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
mysql> desc weibo;
+-------------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------------+---------------+------+-----+---------+-------+
| id | varchar(10) | NO | PRI | NULL | |
| user_id | varchar(12) | YES | | NULL | |
| content | varchar(5000) | YES | | NULL | |
| article_url | varchar(200) | YES | | NULL | |
| original_pictures | varchar(3000) | YES | | NULL | |
| retweet_pictures | varchar(3000) | YES | | NULL | |
| original | tinyint(1) | NO | | 1 | |
| video_url | varchar(300) | YES | | NULL | |
| publish_place | varchar(100) | YES | | NULL | |
| publish_time | datetime | NO | | NULL | |
| publish_tool | varchar(30) | YES | | NULL | |
| up_num | int | NO | | NULL | |
| retweet_num | int | NO | | NULL | |
| comment_num | int | NO | | NULL | |
+-------------------+---------------+------+-----+---------+-------+
14 rows in set (0.00 sec)
|
我们来看下该博主的出生日、性别和粉丝数:
1
2
3
4
5
6
7
|
mysql> select birthday,gender,followers from user;
+------------+--------+-----------+
| birthday | gender | followers |
+------------+--------+-----------+
| 1986-10-01 | 女 | 41000 |
+------------+--------+-----------+
1 row in set (0.00 sec)
|
内容表weibo里,id是内容id,user_id对应user表的id。
发布的微博总数:
1
2
3
4
5
6
7
|
mysql> select count(*) from weibo;
+----------+
| count(*) |
+----------+
| 941 |
+----------+
1 row in set (0.00 sec)
|
最早发布的微博日期:
1
2
3
4
5
6
7
|
mysql> select min(publish_time) from weibo;
+---------------------+
| min(publish_time) |
+---------------------+
| 2021-11-12 11:47:00 |
+---------------------+
1 row in set (0.00 sec)
|
最近发布的微博日期:
1
2
3
4
5
6
7
|
mysql> select max(publish_time) from weibo;
+---------------------+
| max(publish_time) |
+---------------------+
| 2022-02-16 09:53:00 |
+---------------------+
1 row in set (0.00 sec)
|
也就是说,该账号注册于2021年11月12日,这里爬取到的是2021年11月12日到2022年2月16日的微博。
#数据分析
用Tableau连接MySQL。首先,分析发微博数量随日期的变化。由于点赞、评价、转发都是对应单个微博的数据,而一天中可能发布里多条微博,因此需要创建计算字段,获得聚合点赞、评价和转发的度量值。
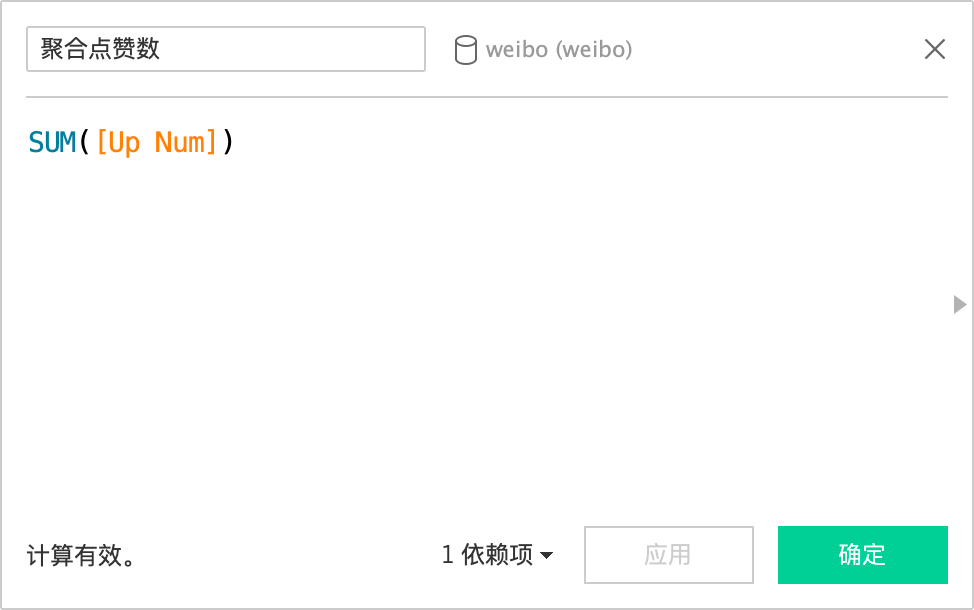

结果如上,可以得出两个猜测:
- 该用户在上线日平均发微博数量为12条,为非常活跃的用户。
- 该用户2021年12月5日左右被禁言了,12月21日取消禁言,大致禁言2周。
- 该用户为期两周后回来的第一天发微博次数只比平均值高一点,但点赞、评论和转发数量均非常高,可见其粉丝非常想念他。
- 该用户2022年2月5日至2月16日,均被限制转发了。
翻开该用户微博证实,其确实在12月5日或6日左右被禁言了,确实是在12月21日左右被解封了,而且其解封后的第一条微博下有大量粉丝留言,这点可以从数据上印证:
1
2
3
4
5
6
7
|
mysql> select publish_time,up_num,comment_num,retweet_num from weibo order by comment_num desc limit 1;
+---------------------+--------+-------------+-------------+
| publish_time | up_num | comment_num | retweet_num |
+---------------------+--------+-------------+-------------+
| 2021-12-21 01:35:00 | 2127 | 1144 | 15 |
+---------------------+--------+-------------+-------------+
1 row in set (0.00 sec)
|
确实该火热的微博是解封当天的,好一出失而复得。
确实该博主也说了自己的微博已经被限制转发了。
该用户是何许人也?为何在短短3个月就获得4万多粉丝,而且与粉丝的互动极好,极具威望?其单日获赞平均数量达到了3831个,评论数达到了1209个,转发数达到了128个,即便是在日均12条微博下也是非常活跃的。
这位博主是外国人吗?
从发微博时段看应该不是:
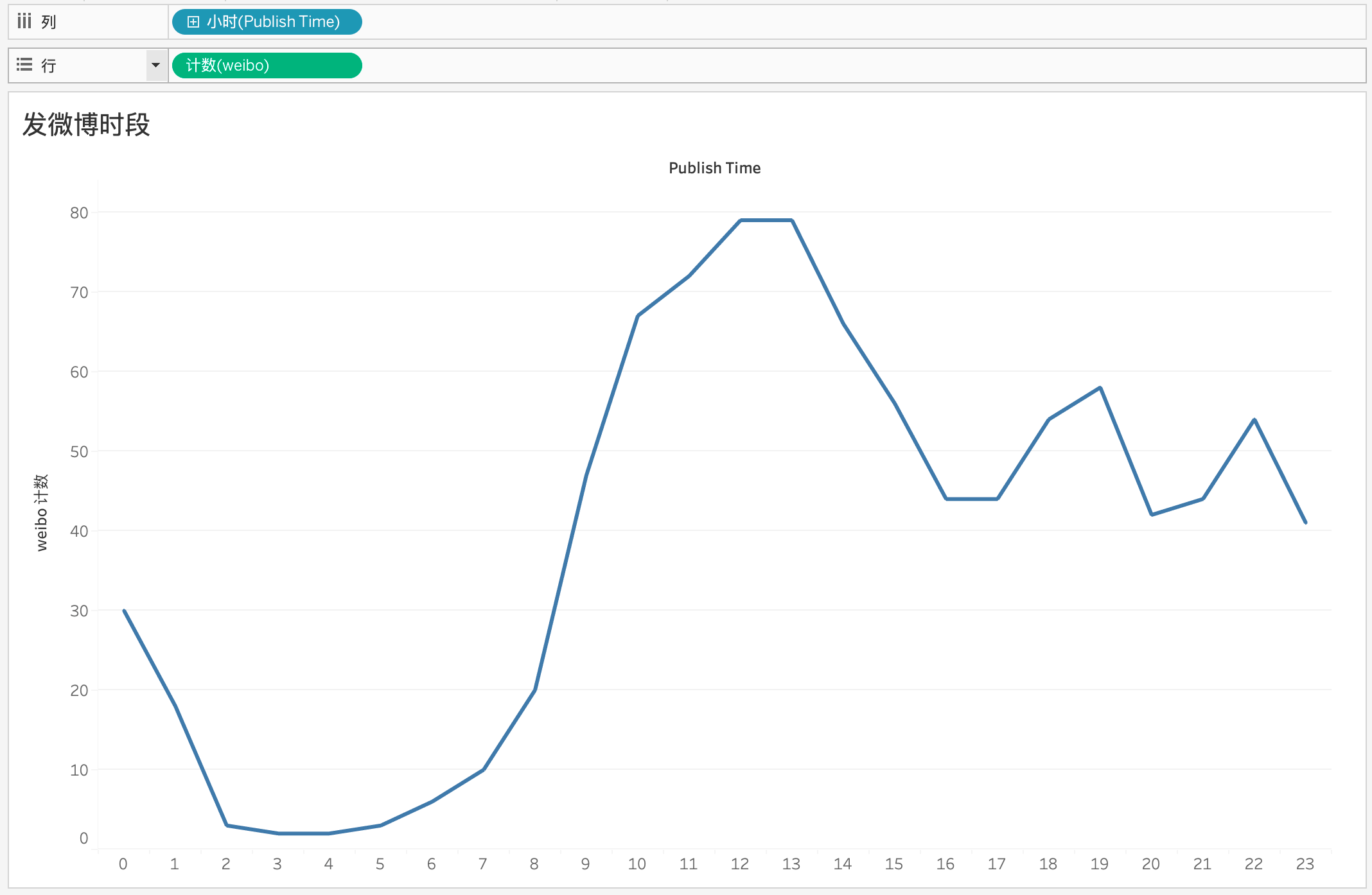
非常标准的作息,猜测这位博主大概平均1点睡觉,7点半起床。
是上班族吗?
不太是,因为每天都发布大量微博,且均集中在一天中的工作时间。
再看看工作日分布:
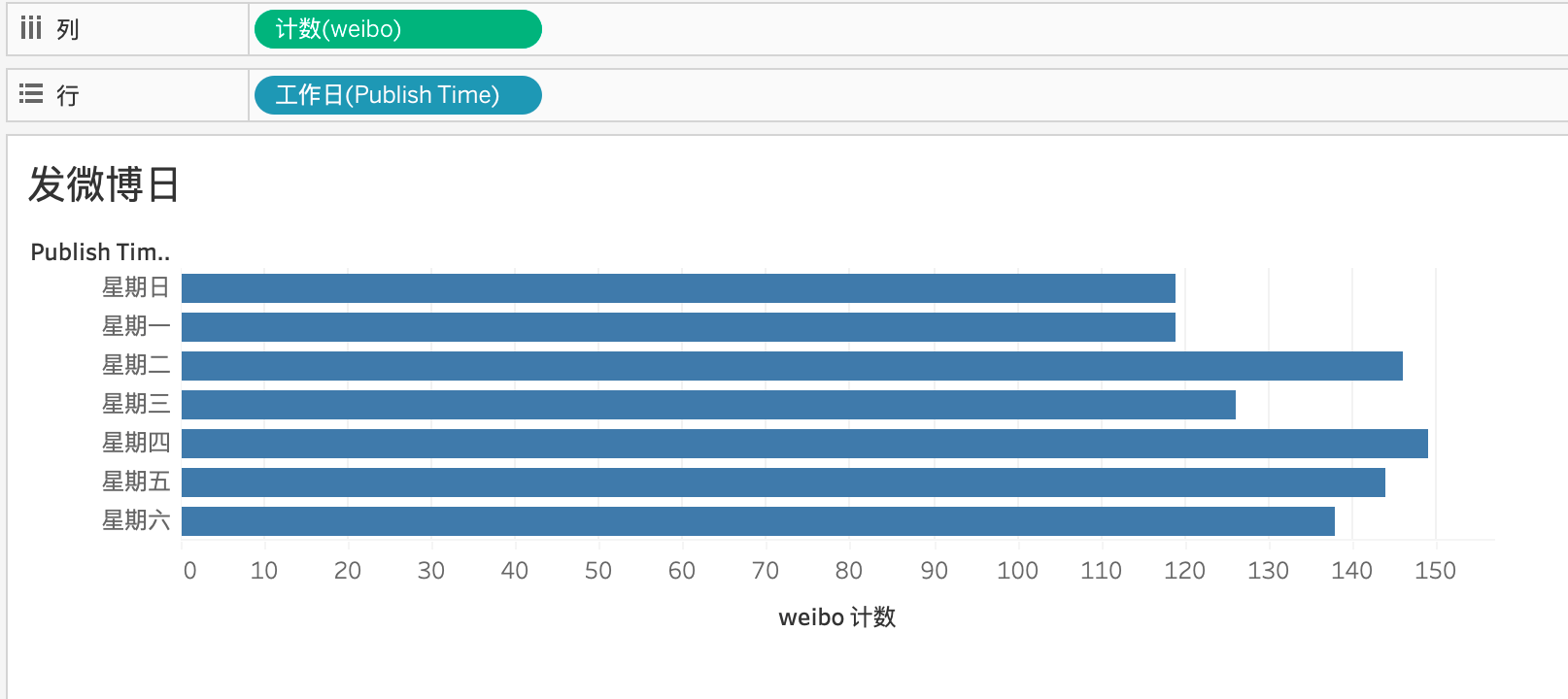
周日和周一发得最少,周二和周四发得最多,而且相差不大。
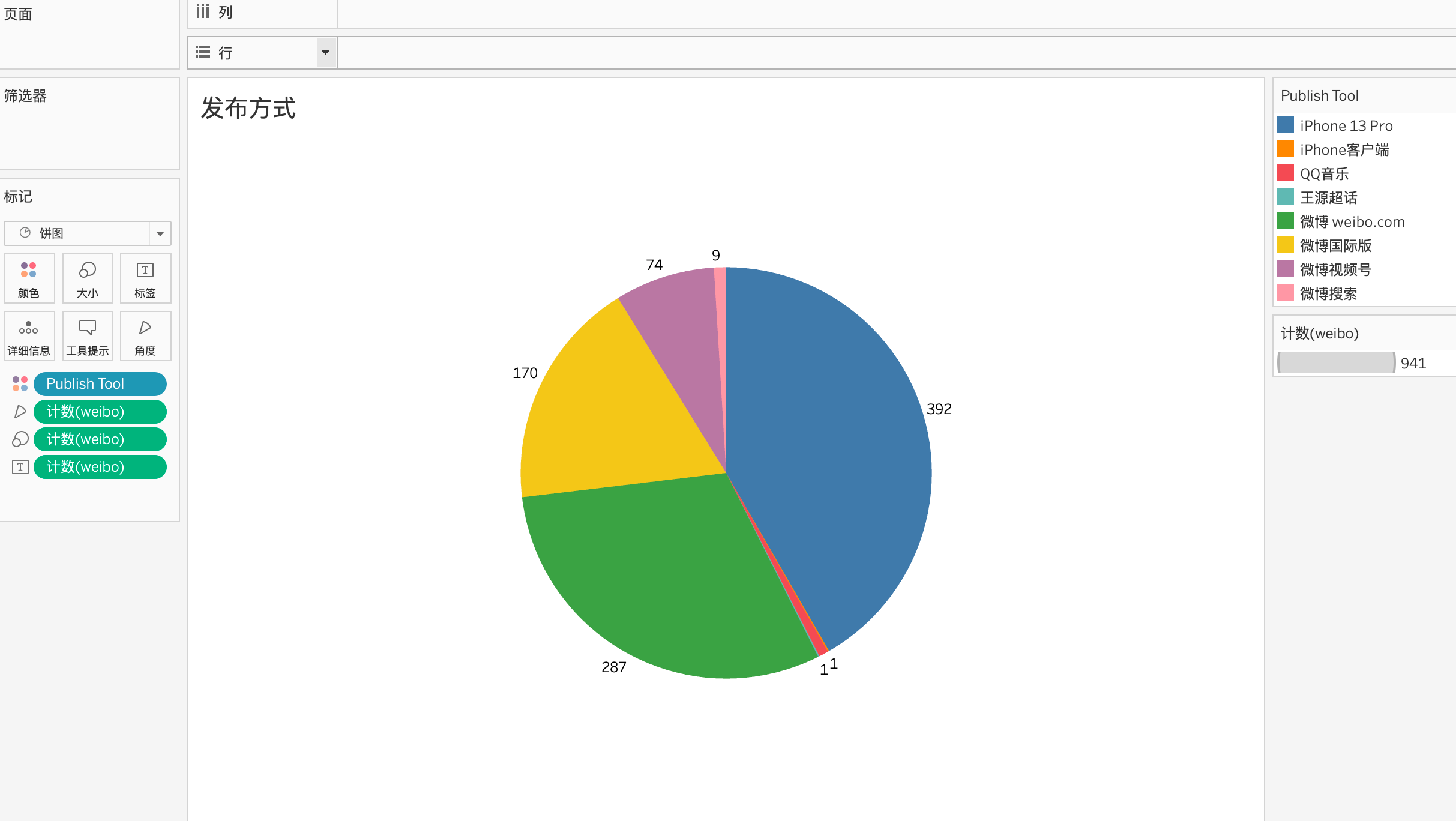
从发布方式上看,使用的手机是iPhone13 pro,weibo.com发布可以看作是从电脑端发出的,其余的可以看出是手机发出的。
这些都不如内容重要。
其微博文本原数据如下:
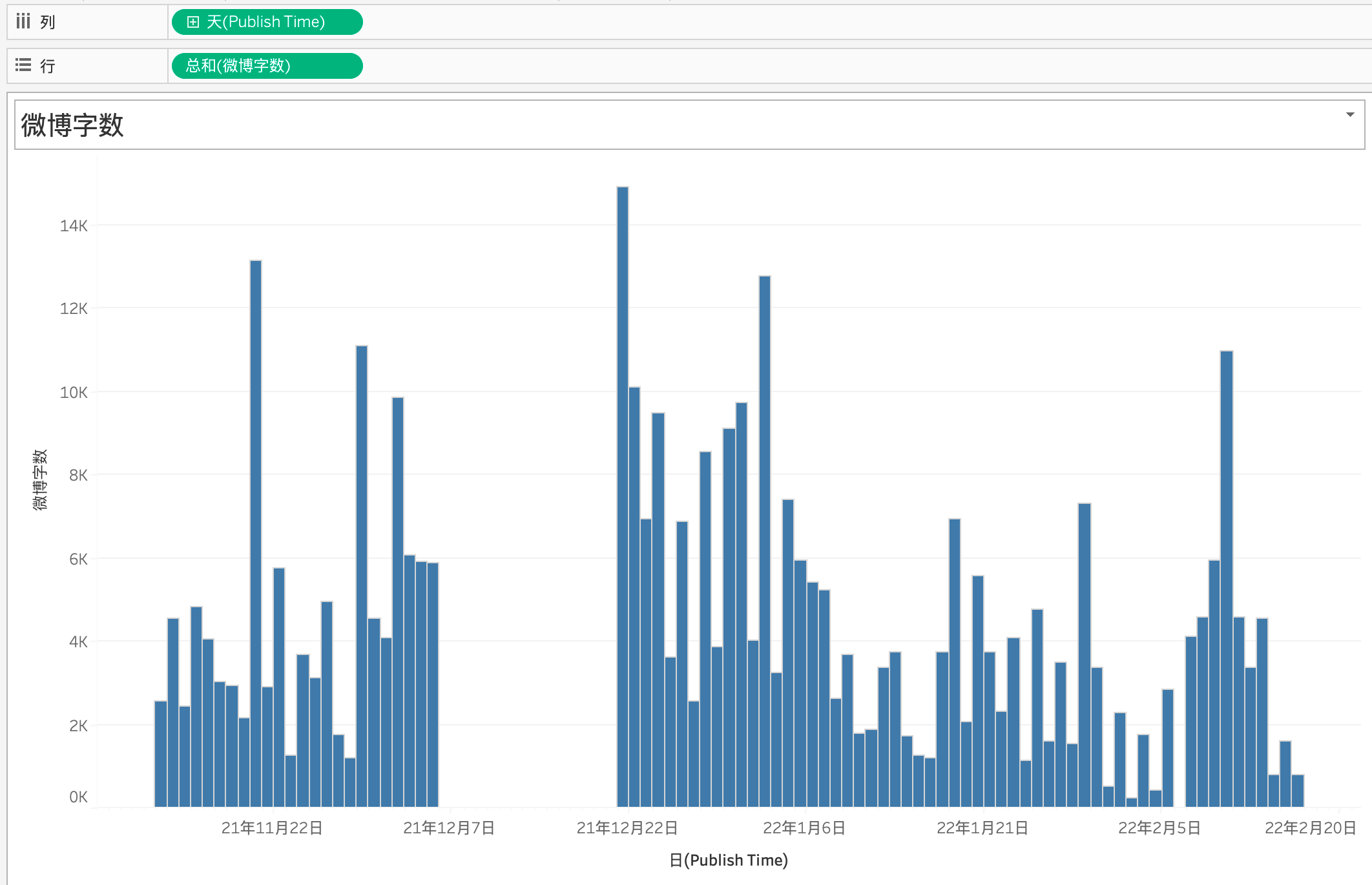
可见,这位博主仅在发微博这一方面单日产出了大量的文字,也可以推测出该博主很有话说,且不属于摄影等之类的博主。
要想最快看出这位博主是做什么的,可以通过词云图来看。
用Python连接数据库,进行数据预处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
import pandas as pd
from sqlalchemy import create_engine
# 初始化数据库连接
# 按实际情况依次填写MySQL的用户名、密码、IP地址、端口、数据库名
engine = create_engine("mysql+pymysql://{}:{}@{}:{}/{}")
# MySQL导入DataFrame
# 填写自己所需的SQL语句,可以是复杂的查询语句
sql_query = 'select content from weibo;'
# 使用pandas的read_sql_query函数执行SQL语句,并存入DataFrame
df_read = pd.read_sql_query(sql_query, engine)
# 初步去除无意义的符号:ASCII空白字符
clean_list = "".join(list(df_read['content'])).split('\xa0')
f = "".join(clean_list)
# 中文词频统计
from wordcloud import WordCloud
from collections import Counter
import jieba
dele = {'。','!','?','的','“','”','(',')',' ','》','《',',', '...', '原图', '全文', '微博', '转发', '组图', '视频'}
words = jieba.lcut(f)
articleDict = {}
articleSet = set(words)-dele
for w in articleSet:
if len(w)>1:
articleDict[w] = words.count(w)
articlelist = sorted(articleDict.items(),key = lambda x:x[1], reverse = True)
top500 = pd.DataFrame(articlelist[0:500],columns=['词语','词频'])
top500.to_csv('词频统计.csv',index=False)
top500
|

将该数据导入Tableau,先用该数据制作气泡图
第一步是将词语拖动到文本:
然后将词频拖给大小,
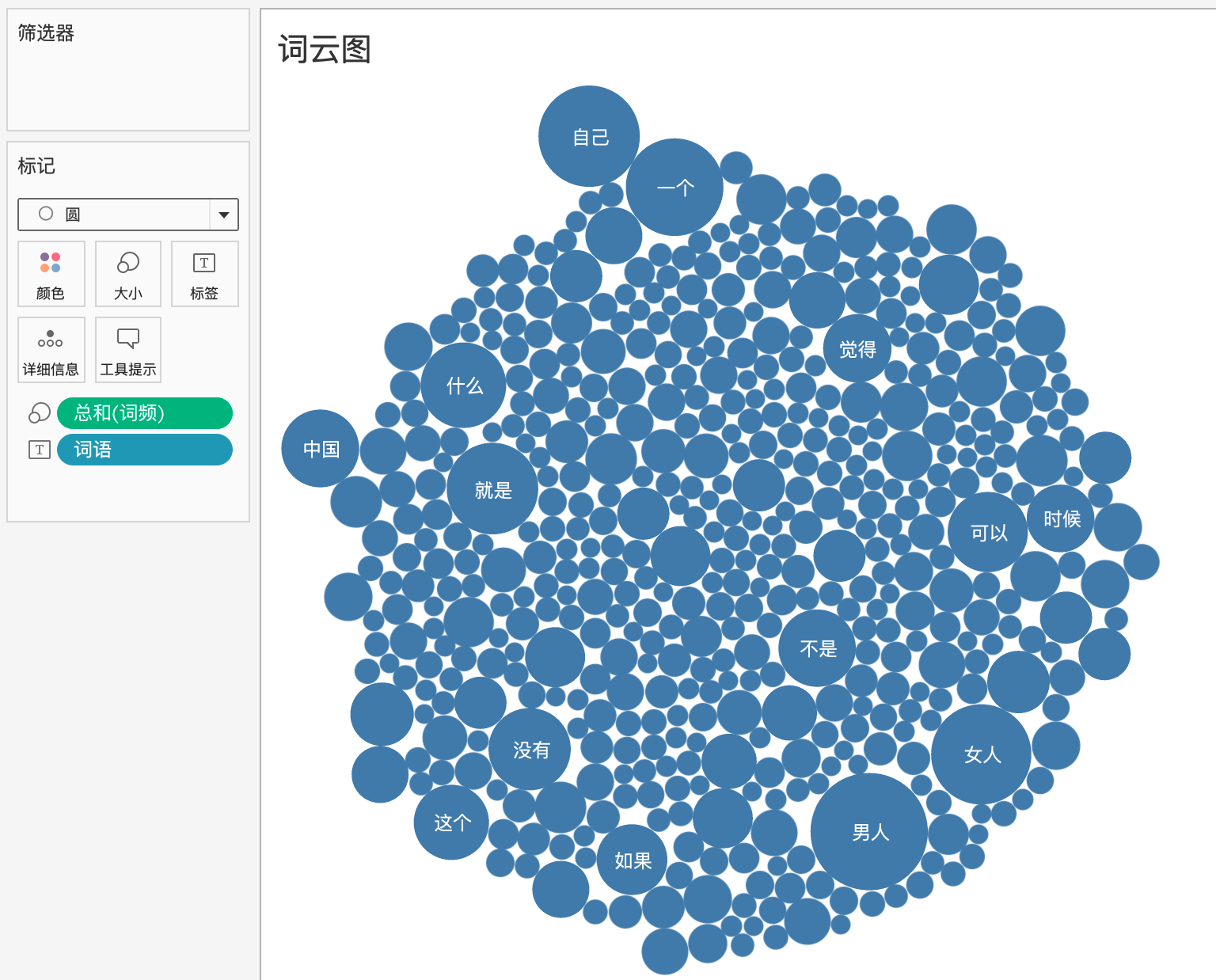
将形状改为文本,并将词语拖动到颜色,用离散的颜色区分即可。

可见,该博主主要关注的是性别方面(男人、女人、女性、女权、孩子、离婚),以及国家政策层面(中国、社会、就是、没有),这500个词涵盖的维度很多,属于知识面很广的博主了。